
Embeddings and Vector Databases
July 1, 2024About 2 min
All the RAG information refer to the Document 1, document 2 the video
The encoding is the key for the RAG.
embedding solutions
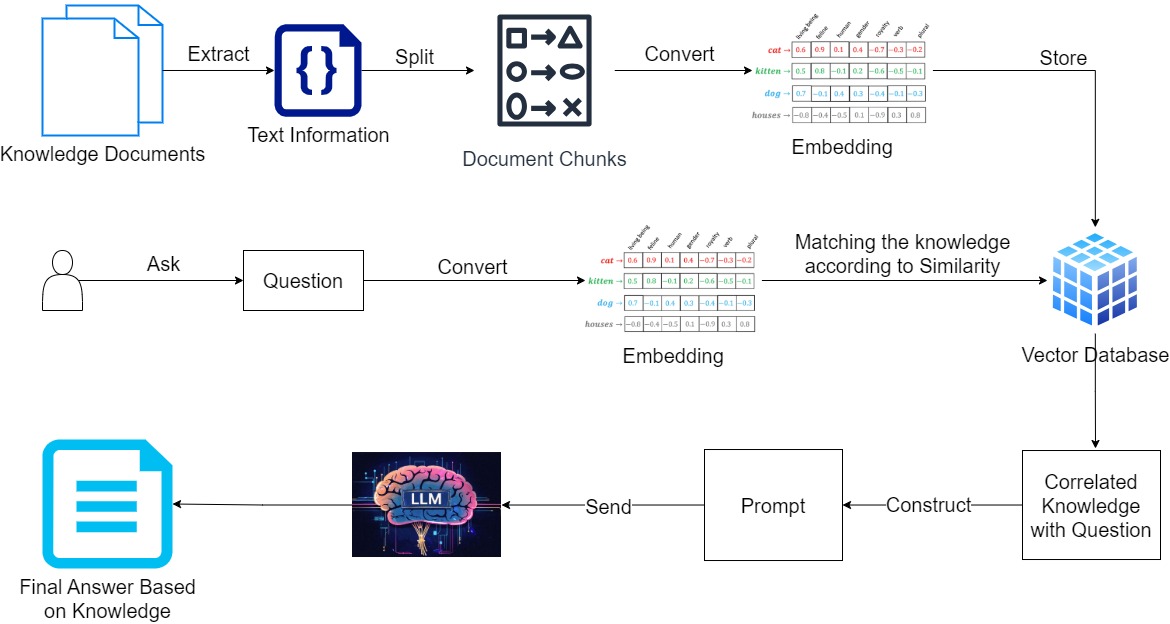
How RAG Works
Categories of RAG
RAG can be classified into three classes according to the complexity, which are Naive RAG, Advanced RAG and Modular RAG.
| Type | Description |
|---|---|
| Naive RAG | Naive RAG is the most basic form of RAG technology, also known as classic RAG. It includes three basic steps: indexing, retrieval, and generation. The indexing stage divides the document library into short chunks and builds a vector index. The retrieval stage retrieves relevant document fragments based on the similarity between the question and the chunks. The generation stage generates answers to the questions based on the retrieved context. |
| Advanced RAG | Advanced RAG is an optimization and enhancement of Naive RAG. It includes additional processing steps, which are performed before and after data indexing and retrieval. It includes more sophisticated data cleaning, document structure design, and metadata addition to improve text consistency, accuracy, and retrieval efficiency. It uses question rewriting, routing, and expansion to align semantic differences between questions and document blocks before retrieval. It avoids the "Lost in the Middle" phenomenon through re-ranking after retrieval, or shortens the window length through context filtering and compression. |
| Modular RAG | Modular RAG introduces more specific functional modules, such as query search engine, fusion of multiple answers, etc. Technically, it integrates retrieval and fine-tuning, reinforcement learning, etc. In terms of process, RAG modules are designed and arranged, and a variety of different RAG modes appear. Providing greater flexibility, the system can select the appropriate combination of functional modules according to application requirements. The introduction of modular RAG makes the system more free and flexible, adapting to different scenarios and requirements. |
Key Components in RAG
| Components | Description |
|---|---|
| Intent Understanding | The Intent Understanding module is responsible for accurately grasping the user's queries, determining their intent and topic. It handles the ambiguity and non-standard nature of user questions, providing clear task objectives for subsequent processes. |
| Document Parsing | The Document Parsing module processes documents from various sources, including PDFs, PPTs, Neo4j, etc. This module converts document content into a structured format suitable for knowledge retrieval. |
| Document Indexing | The Document Indexing module segments parsed documents into short chunks and builds vector indexes or uses full-text indexing for text retrieval, enabling the system to quickly find document fragments relevant to user queries. |
| Vector Embedding | The Vector Embedding module maps content from document indexes into vector representations for similarity calculations. This helps the model understand relationships between documents better, improving the accuracy of knowledge retrieval. |
| Knowledge Retrieval | The Knowledge Retrieval module calculates similarity scores based on user queries and vector embeddings or text retrieval. This step ensures semantic relevance between queries and documents, ensuring accurate retrieval. |
| Re-ranking module | The Re-ranking module reorders the document library after knowledge retrieval to avoid the "Lost in the Middle" phenomenon, ensuring the most relevant document fragments appear first. |
| Large Model Answering | The Large Model Answering module uses large-scale language models to generate final answers. This module integrates retrieved contexts to produce coherent and accurate text responses. |
| Others | Additional functional modules can be introduced based on specific application requirements, such as query search engines, merging multiple answers, etc. Modular design enhances system flexibility, enabling selection of appropriate functional module combinations for different scenarios. |