
- Information came from George in Discord channel
meeting summariesat 1:33pm 4 July 2024. - This is the notes for paper "Polaris: A Safety-focused LLM Constellation Architecture for Healthcare". The online version is here.
- Notes on Drawio
Abstract
We develop Polaris 1, the first safety-focused Large Language Model (LLM) constellation for real-time patient-AI healthcare conversations. Unlike prior LLM works in healthcare, which focus on tasks like question answering, our work specifically focuses on long multi-turn voice conversations. Our one-trillion parameter constellation system is composed of several multi-billion parameter LLMs as co-operative agents: a stateful primary agent that focuses on driving an engaging patient-friendly conversation and several specialist support agents focused on healthcare tasks performed by nurses, social workers, and nutritionists to increase safety and reduce hallucinations. We develop a sophisticated training protocol for iterative co-training of the agents that optimize for diverse objectives.
We train our models on proprietary data, clinical care plans, healthcare regulatory documents, medical manuals, and other medical reasoning documents. We further align our models to speak like medical professionals, using organic healthcare conversations and simulated ones between patient actors and experienced care-management nurses. This allows our system to express unique capabilities such as rapport building, trust building, empathy and bedside manner augmented with advanced medical reasoning.
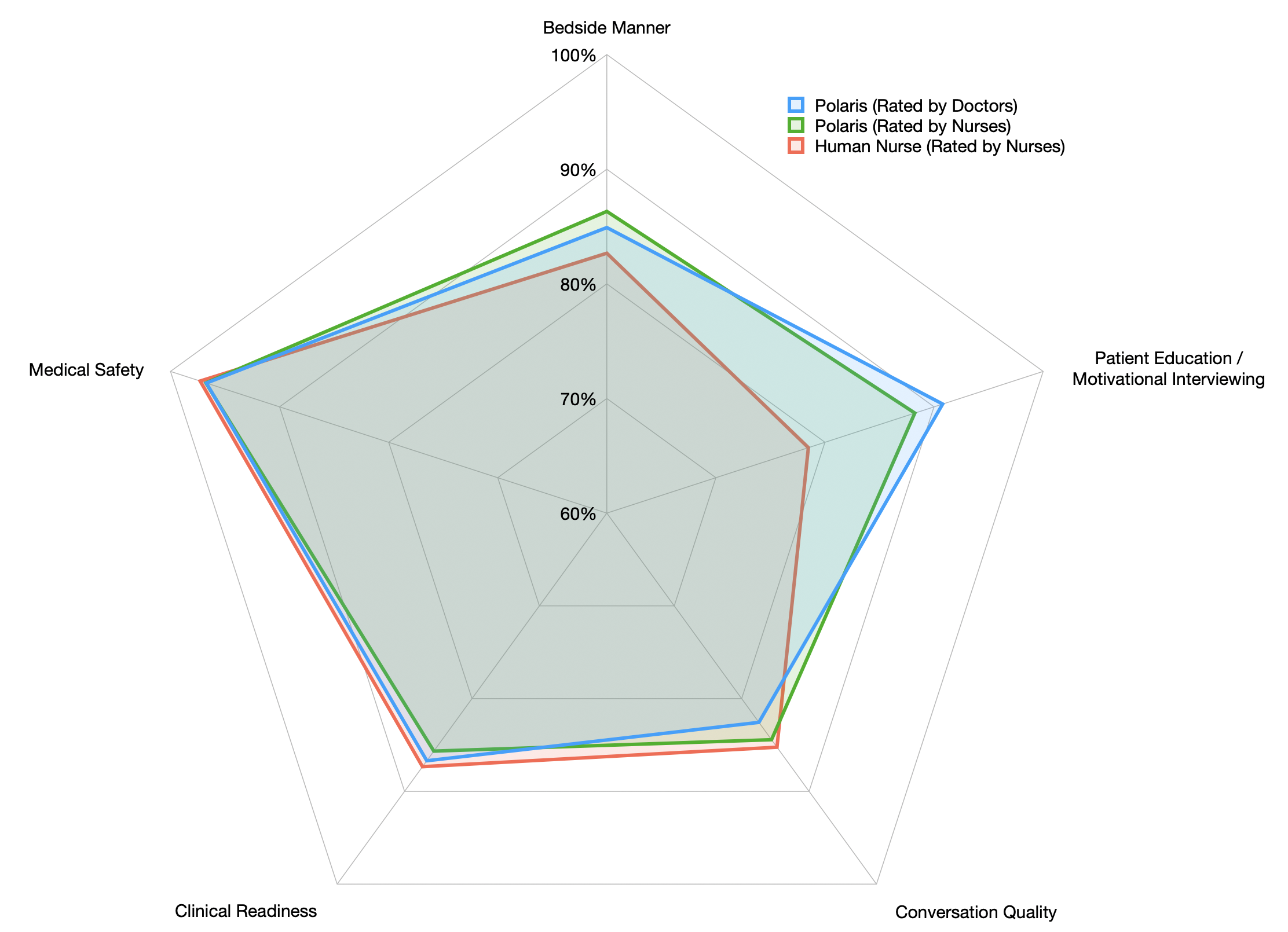
Finally, we present the first comprehensive clinician evaluation of an LLM system for healthcare. We recruited over 1100 U.S. licensed nurses and over 130 U.S. licensed physicians to perform end-to-end conversational evaluations of our system by posing as patients and rating the system on several fine-grained measures. We demonstrate Polaris performs on par with human nurses on aggregate across dimensions such as medical safety, clinical readiness, patient education, conversational quality, and bedside manner. Additionally, we conduct a challenging task-based evaluation of the individual specialist support agents, where we demonstrate our LLM agents significantly outperform a much larger general-purpose LLM (GPT-4) as well as one from its own medium-size class (LLaMA-2 70B).
Introduction
Note
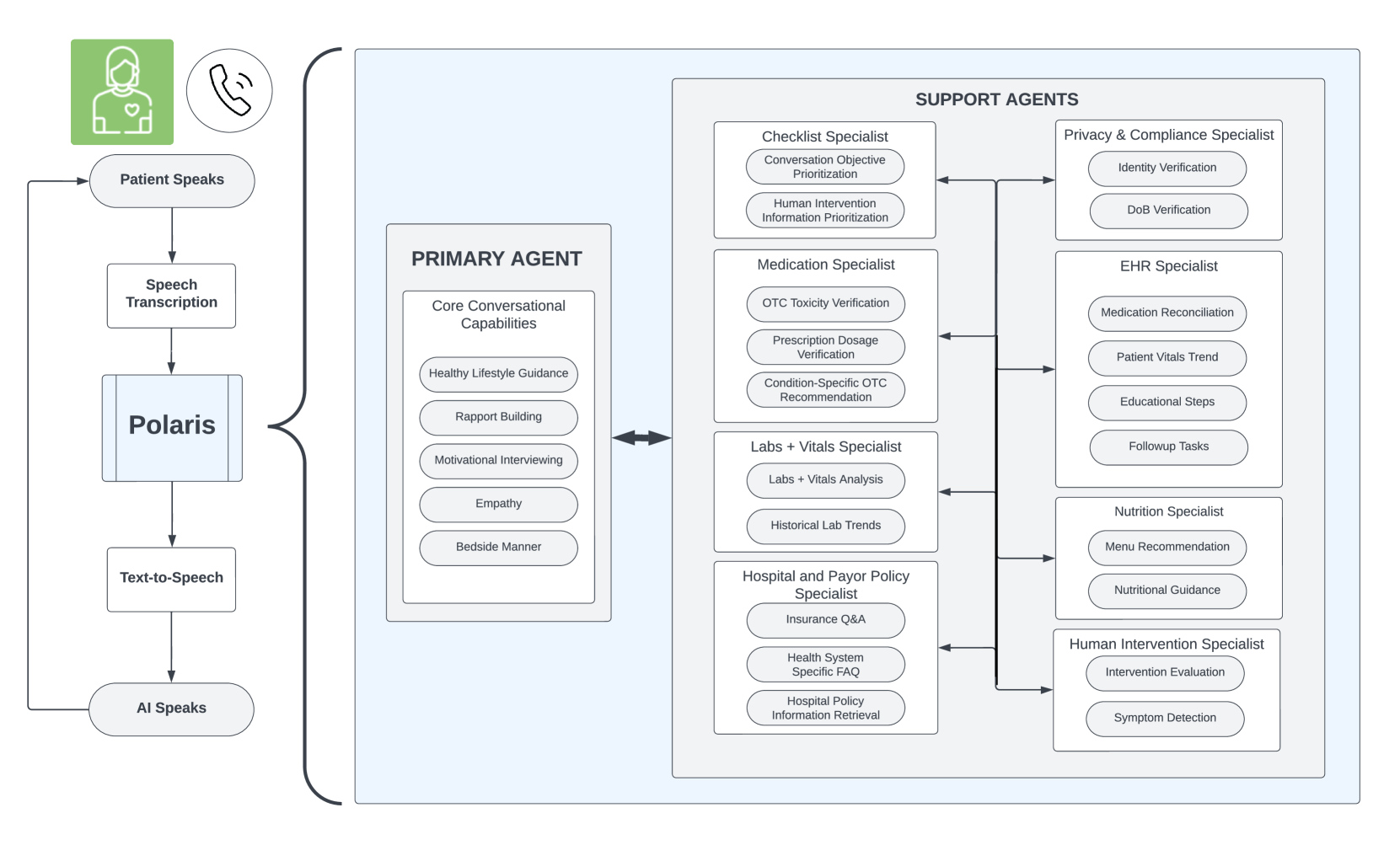
(a)Overview of our architecture, comprising of the Automatic Speech Recognition (ASR) for speech transcription, Polaris for processing the textual utterances, and Text-To-Speech (TTS) for the audio output. The constellation within Polaris contains a primary LLM agent driving the conversation, and several specialist LLM agents providing task-specific context to it.
Recent progress in large language models (LLMs) has shown their impressive capability to plan, reason and interact with humans for a variety of tasks such as web search web, coding Bird et al. (2023), and intelligent content creation Ray (2023). The scaling of LLMs and the datasets used to train them, together with new architectural advances has contributed greatly to the advances in AI capabilities, and shown to surpass human performance in various benchmark tasks sur. These new capabilities are enabling real-world applications that were impossible until very recently such as those in healthcare.
Healthcare specialization. Amidst the several domains and applications, healthcare remains a high-stake domain where errors may have fatal implications. The advent of GPT-4 Achiam et al. (2023) has led to a profound surge in the use of AI for healthcare applications, including clinical note and electronic health record processing (see Lee et al. (2023) for overview). While systems like MedPALM Singhal et al. (2023a) and GPT-4 have shown impressive results in general medical benchmarks like USMLE, recent work shows significant error rate for more specialized use-cases like pediatrics Barile et al. (2024). Among the failures, researchers observe that the AI systems struggle to spot known relationships between conditions that an experienced physician would look for, e.g., for a patient with autism, a physician might check for dietary deficiencies. Jacobsen and DeNiro (2017). The researchers note that these systems could be improved by selectively training on accurate and high quality medical literature, not just general articles over the internet, which are typically what most LLMs are trained on. Furthermore, it is possible that the base knowledge about autism leading to nutrient deficiencies is present in the LLMs; what is missing is the medical reasoning to connect the dots (i.e., some patients with autism exhibit narrow dietary preferences, which can then lead to nutrient deficiencies).
Conversational Healthcare Systems. Most of the existing works for generative AI in healthcare are focused on tasks like medical question-answering Singhal et al. (2023b) and EHR summarization Veen et al. (2024). There are very few works focusing on natural dialogue between caregivers and patients. More recently, Tu et al. developed Articulate Medical Intelligence Explorer (AMIE) Tu et al. (2024a), which outlines the importance of diagnostic dialogue to enable physicians to make diagnoses and develop management plans. AMIE is presented as a tool for physicians, and focused on diagnostic use cases. There remains a gap in work addressing the broader range of conversations between a care team and a patient that are neither diagnostic, nor directed to clinical decision making, such as inquiring whether a patient is adhering to their prescription, whether they are following the physician’s pre- and post-procedure directions, and general wellness check-ins. While non-diagnostic, these conversations must still be medically accurate, and critically, must build rapport and trust with the patient to make them feel safe, supported, and confident in their care, while communicating with empathy and bedside manner. Such relationship has shown to lead to better patient satisfaction and, ultimately, better outcomes in real world Derksen et al. (2013). General-purpose LLM’s, however, are not optimized for such objectives. Furthermore, these LLM’s are also not optimized for real-time, voice-based conversations, which can be quite different from text-based conversations. For instance, factors such as response length, quality of voice, pauses and interrupts greatly impact the subjective experience.
The case for AI-based Healthcare Agents. The US healthcare industry is facing a massive shortage of healthcare workers, that became even more apparent after the COVID-19 pandemic ora. Exacerbated by burnout, stress and financial conditions, 16.7% of hospitals anticipated a critical staffing shortage in 2023 according to the Department of Health and Human Service AHA. The U.S. Bureau of Labor Statistics estimates the need to fill over 200,000 nursing positions every year until 2031 Fac. A 2023 survey found that 28.7% percent of nurses were considering to leave their jobs. The trend in the decline of the US workforce indicates a shortage of more than 4 million workers nationwide by 2026 ora. In the meantime, the demand for healthcare continues to grow as the population continues to age. There are currently 46 million adults over 65, and it will increase to 64 million by 2030, and 90 million by 2050 Agi.
Given this massive gap in supply and demand for healthcare workers, and the recent promise of Generative AI to supercharge productivity, we focus on developing a non-diagnostic technology for healthcare workforce augmentation, which we denote as super-staffing. In this work, we develop autonomous generative AI healthcare agents that can safely converse with patients on medical topics. Our goal is to improve patient healthcare outcomes by providing a scalable and safe system that can handle non-diagnostic communications. Such a system will allow the human healthcare providers to focus on top-of-license diagnostic and clinical tasks, thereby helping to alleviate staffing shortages. The agents are designed with built-in safety guardrails that ensure appropriate human supervision.
Our solution is a multi-agent system with highly specialized healthcare LLMs. The following are the primary contributions of our work.
Architecture and Training. We develop a unique multi-agent LLM constellation architecture optimized for real-time healthcare conversation. We employ a primary conversational agent with several specialist support agents for a patient-friendly and medically accurate conversation. The primary agent is trained to be aligned with nurse-like conversations geared for building trust, rapport and empathy with patients, as well as accomplishing healthcare-specific tasks typically performed by nurses, medical assistants, social workers, and nutritionists. We develop techniques to make the primary agent stateful to navigate through a long checklist of care protocols. Our support agents are specialized in healthcare tasks that require a high-level of accuracy, such as confirming that the patient’s reported medicine consumption aligns with the dosage prescribed by their physician, determining whether the patient’s reported OTC drug consumption is within the manufacturer’s recommended range, understanding which medicine the patient is referring to (i.e., patients often struggle with correctly pronouncing drug names, and may confuse ones that sound similar), retrieving current and historical lab results from the patient’s EHR, guiding the patient’s food choices to align with their prescribed diet, etc. The specialist agents provide the relevant context to the primary agent in a message-passing framework, which drives the main conversation.To this end, we develop custom training protocols for conversational alignment using organic healthcare conversations and simulated ones using patient actors and nurses (U.S. licensed) with agents- and clinicians-in-the-loop for co-operative learning.
Safety. We adopt a three-pronged approach to safety comprised of: (1) A 70B-100B primary model trained using evidence based content; (2) a novel constellation architecture with multiple models totaling over one trillion parameters, in which a primary LLM is supervised by multiple specialist support models to improve medical accuracy and substantially reduce hallucinations; (3) built-in guardrails that bring in a human supervisor when necessary.
Evaluation. To the best of our knowledge, we perform the first extensive real-world evaluation of a healthcare LLM system in which we recruited over 1100 US-licensed nurses and over 130 U.S.-licensed physicians posing as patients for our system. This is focused on an integrated system-level conversational evaluation on dimensions such as medical safety, readiness and bedside manners where we demonstrate parity with human nurses on several key metrics. We also perform a challenging component-level evaluation where we demonstrate that our medium-size specialized agents massively outperform a much larger state-of-the-art general-purpose LLM (GPT-4) on the healthcare tasks as well as outperform an LLM from its own parameter size class (LLaMA-2 70B).
2. System Overview
Polaris is architected as a constellation of a primary and multiple specialist LLMs. It also includes the supporting system which orchestrates control flow, inter-model message passing and maintains conversation state. The system is designed to achieve better domain-specific interactions compared to a single general purpose LLM. The healthcare conversation domain is apt for showcasing the value of this paradigm as there are many competing objectives and requirements, including a special emphasis on safety and verification. We further explain the problem domain, system architecture and also provide relevant details on the constituent models in the following sections.
2.1 Objectives and Use Cases
We develop Polaris for patient-facing, real-time healthcare conversation. The objective of this system is to perform low risk non-diagnostic tasks typically performed by nurses, medical assistants, social workers, and nutritionists. The system is constructed for voice-based interaction, as phone calls are the dominant method of communication for many high-volume and high-value healthcare use cases. Building a voice-based autonomous agent is a challenging problem due to factors such as voice quality, pitch, tone, response length, interruptions, and communication delay. Additionally, Polaris has to take into account errors introduced by the Automated Speech Recognition (ASR) system in the transcription of the audio signal, with a particular focus on the complexity of recognizing healthcare-specific words and phrases (e.g., complex medication names and lab values).
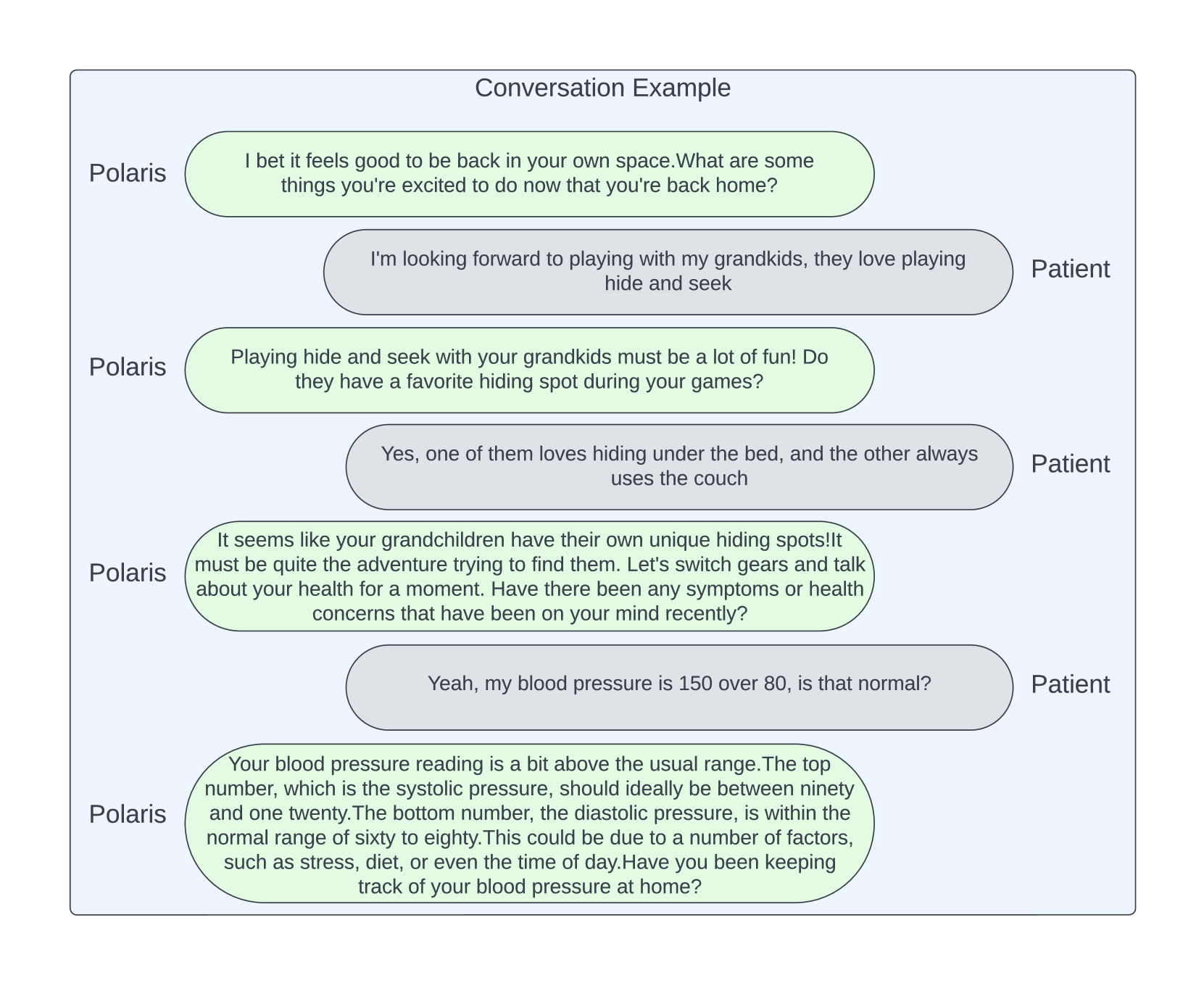
We train our healthcare agents to accomplish a number of tasks that can be completed via phone calls or voice-only interactions. Typical objectives for these tasks include general check-in on patient wellness, reviewing compliance with prescribed medicine regimes, confirming appointment details, reviewing procedural logistics, performing diet reviews, communicating lab results, etc. Given that the number of tasks in a typical care protocol can be quite large and extensive, the agent must be able to maintain and update conversation state with each patient, ensuring that all tasks are completed. The task completion rate directly impacts the success rate for the call. At the same time, we train these agents to have natural conversations that mimic what human caregivers would say, rather than a mere question-answering system as in prior works. For instance, the agent must be able to answer any question the patients may have, address their concerns, and otherwise handle tangential discussions in the conversation. This makes it particularly challenging for the agent to engage in deep conversations with the patient, given that the style, tone and content of these conversations can be quite different from the model’s original training dataset. Such conversation fluidity coupled with its state awareness and medical accuracy remains at the crux of all our design and architectural decisions. Furthermore, we design our system to build trust and rapport with patients, learning about their personality and preferences to demonstrate good bedside manner and leading to higher patient satisfaction and potentially better health outcomes. Our system is deeply specialized in many different medical conditions and procedures. For the purpose of this report, we highlight three representative outbound-call use cases including follow-up calls for post-discharge congestive heart failure (CHF), ongoing care for chronic kidney disease (CKD), and pre-operative check-in for colonoscopy. Figure 2 shows an overview of the different capabilities of our system.
Key Information
Typical objectives
- general check-in on patient wellness,
- reviewing compliance with prescribed medicine regimes,
- confirming appointment details,
- reviewing procedural logistics,
- performing diet reviews,
- communicating lab results,
- etc.
2.2 Constellation Architecture
The core part of Polaris is the multi-agent LLM constellation. As opposed to a general large model performing many different tasks with varying performance, we break down the faculty into medium-size specialist models with consistent high performance. This is beneficial in settings like ours to optimize for tasks with competing objectives, while keeping the latency low for a real-time application. For instance, this allows us to optimize the primary language model for conversational fluidity, rapport-building and empathetic bedside manner with patients.
Simultaneously, we focus on developing specialized agents with capabilities that serve a dual purpose: (a) assist the main LLM with relevant healthcare-specific context (e.g., A patient with chronic kidney disease stage 3b is recommended to avoid common NSAIDs like advil, motrin); (b) provide a layer of safety to double-check the information provided by the main model (e.g., 40mg of Lasix twice a day vs. 80mg of Lasix once a day). Each of these agents is tied to specific abilities such as confirming that the patient’s reported medicine consumption aligns with the dosage prescribed by their physician, determining whether the patient’s reported OTC drug consumption is within the manufacturer’s recommended range, understanding which medicine the patient is referring to (i.e., patients often struggle with correctly pronouncing drug names, and may confuse ones that sound similar) retrieving current and historical lab results from the patient’s EHR, guiding the patient’s food choices to align with their prescribed diet, etc.
While Polaris has many such agents, we focus on only a subset of them for illustration. Finally, these agents co-operate to solve a complex task. For instance, the patient utterance ‘‘I am taking dulaglutide. I saw my hemoglobin a1c was 5 - is that normal?’’ requires both the lab agent and the medication agent to work together with the primary agent to formulate the response ‘‘a hemoglobin a1c of 5 is within the normal range and lower than your previous value of 6.5. Your dulaglutide does decrease your hemoglobin a1c level’’.
2.3 Orchestration
The internal state of Polaris evolves as a result of the primary agent’s interactions with the user and the message passing conducted by the support agents. To explain this more clearly we adopt the following notation for the system components:
- Agents: Let
- Conversation History: Let
- Agent-Specific Prompts: Let
- Support Agent Outputs: Let
- State Changes: Let
- Prompts: The prompt for the primary agent at turn
- Short-Horizon Tasks: These can be represented as additional prompt snippets, e.g.,
Polaris mediates the message passing between agents with deterministic imperative programming. This allows us to keep the output space of the support agents well-constrained and implement control-flow logic to support customized protocols. The tasks which are given to the primary agent are systematically formatted and use synthesized information from multiple agents when applicable. This framework facilitates a cooperative approach to complex dialogue generation, where multiple agents contribute to the overall conversation dynamics. An overall step of the constellation system is described in Algorithm 1.
2.4 LLM Details
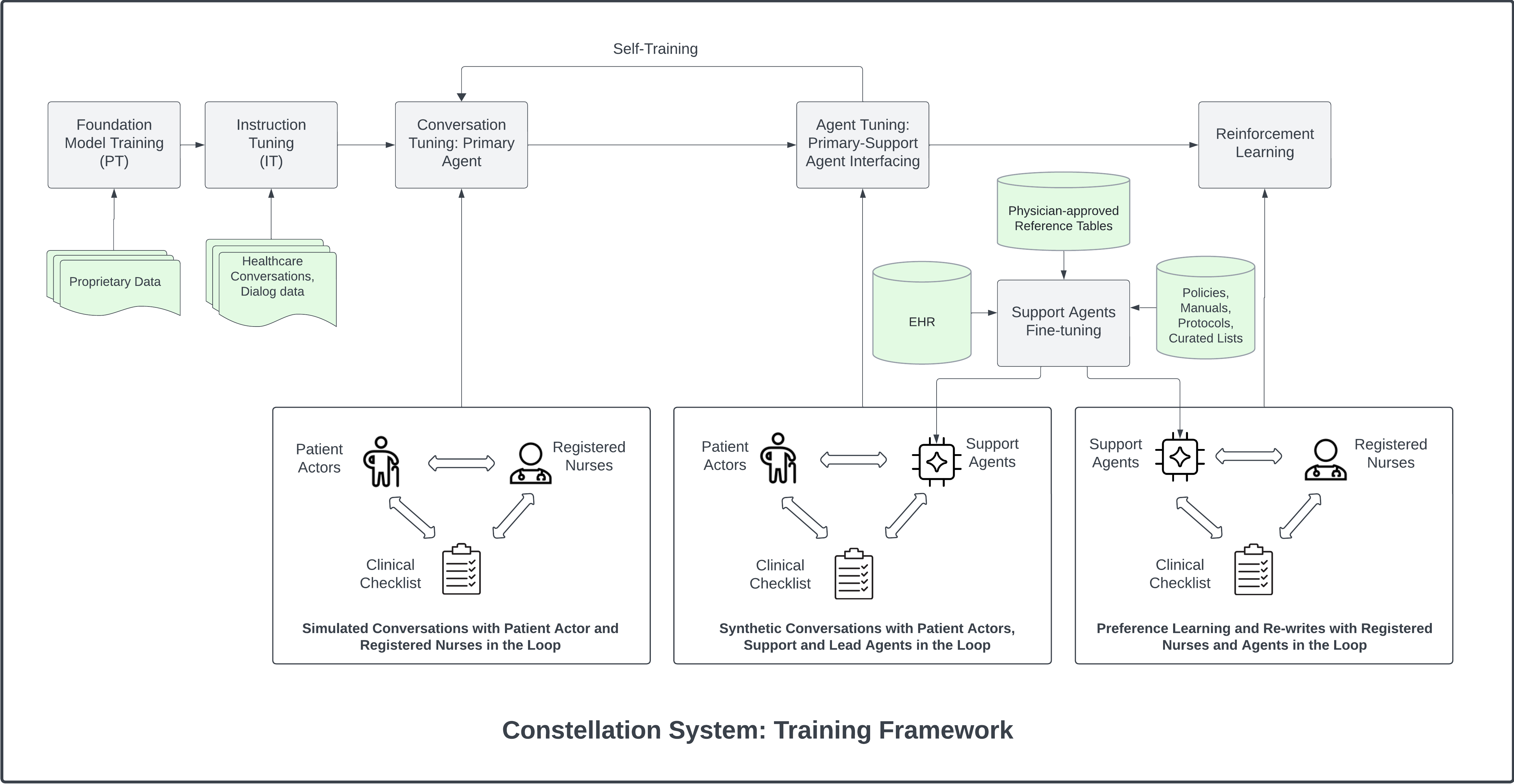
Our LLM architecture designs and training choices are constrained by the requirement to serve the model in real-time as part of our LLM constellation. As a result, we employ a diverse set of LLMs for the support agents ranging from 50B to 100B parameters, whereas the primary agent is always a medium-size LLM (70B - 100B parameters). All of our models follow a decoder-only transformer-based architecture, and contain between 30 and 100 layers. We use Grouped Query Attention (GQA) Ainslie et al. (2023) to achieve faster inference speeds and reduced memory footprint when storing the KV cache during inference, which in turns allows us to serve larger batch sizes for increased throughput. Different models use different tokenizers depending on the use case and the need for specialized medical terminologies (such as drug names), with vocabulary sizes ranging from 30,000 to 200,000 tokens. The implementation of the attention mechanism employs Flash Attention 2 Dao (2023), which makes the training and inference stages faster, with lower memory footprint and more efficient scaling to longer sequence lengths. All of our models use RMSNorm normalization layers Zhang and Sennrich (2019), SwiGLU activation functions Shazeer (2020), and Rotary Positional Embeddings (RoPE) Su et al. (2024). The maximum context window varies from model to model, ranging from 4,096 to 32,768 tokens. The training runs were performed using a distributed, multi-GPU setup, using several hundred Nvidia H100 GPUs with DeepSpeed Rasley et al. (2020).

The primary agent is trained in 3 stages: General Instruction Tuning, Conversation and Agent Tuning, and RLHF. The training and dataset details for the primary agent are discussed in Section 3. The rest of the models are trained using human-labeled datasets, as defined in the respective sections for each agent.
During inference, we deploy some of our models in bf16 precision and others in int8 precision (using weight-only quantization), depending on the latency and accuracy requirements.
Key Information
Primary agent training
- General Instruction Tuning
- Conversation and Agent Tuning
- RLHF
3 Conversational Alignment
In the healthcare domain, the development of a patient-focused clinical framework requires an intelligent conversational agent. This agent has to be designed to foster empathetic engagement with patients, skillfully addressing their concerns and assessing health conditions, be a motivational coach and adopt the multifaceted role of a dietary mentor. It has access to all relevant patient information and medical history to reason and navigate through a complex clinical conversation.
3.1 Data
The development of conversational agents capable of engaging in meaningful and accurate clinical discussions represents a significant challenge. This challenge is compounded by the lack of datasets specifically tailored for training models in the nuanced context of healthcare conversations. Our work addresses this critical gap by leveraging a unique compilation of dialogues, including simulated interactions between registered nurses and patient actors. These dialogues form the cornerstone of our approach to developing a conversational agent with the proficiency to navigate a wide array of clinical discussions. To enhance the agent’s reasoning capabilities, instruction-following proficiency, and domain-specific knowledge – we augmented these datasets by introducing diverse kinds of instructions and tasks geared for multi-hop reasoning. For instance, given a user utterance “my shoes do not fit”, the agent should be able to reason about “swollen ankle → sign of fluid retention → sign of exacerbating CHF conditions”.
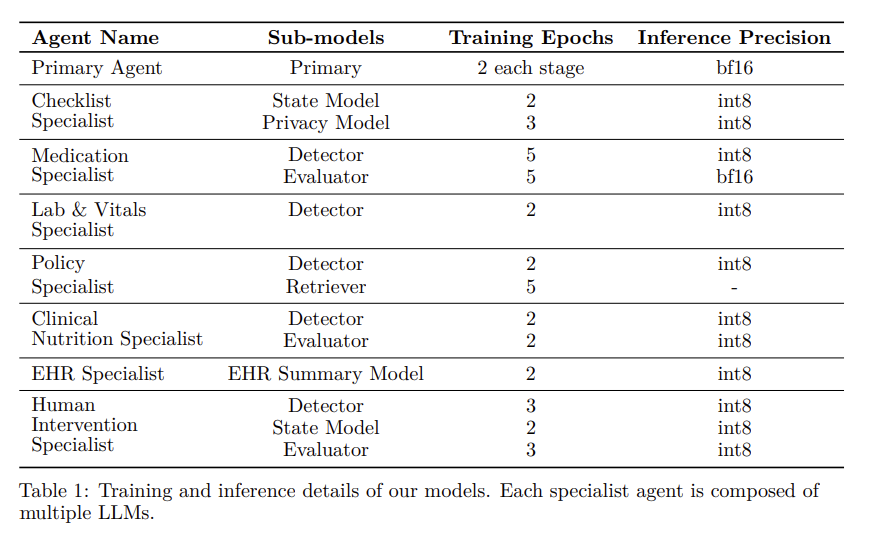
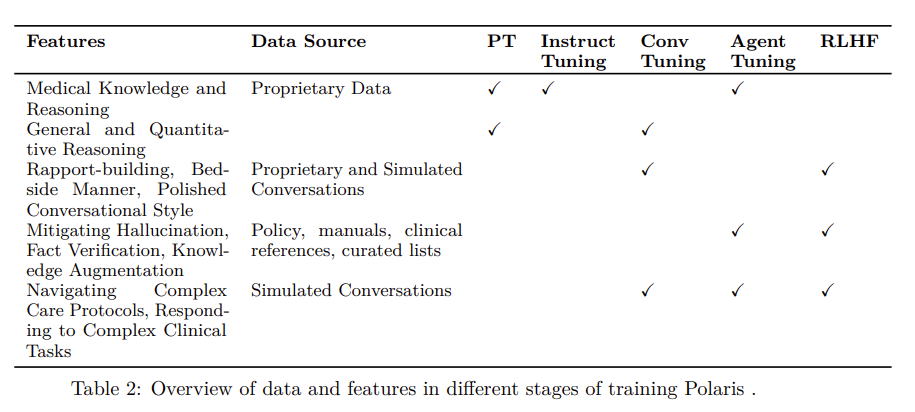
3.1.1 Foundation Model Training Data
We first train our foundation model on a massive collection of proprietary data including clinical care plans, healthcare regulatory documents, medical manuals, drug databases, and other high-quality medical reasoning documents. The objective of this phase is to incorporate fine-grained medical knowledge, reasoning and specialized numerical reasoning (e.g., dosage calculations). We further annotated some of the medical datasets with reasoning chains to further enhance the medical reasoning capabilities of the model. Figure 31 shows one of the examples of the medical question answers we leveraged for training our foundation model.
3.1.2 Simulated Conversations
The nature of our conversational objectives requires specialized data. The agent should
be able to maintain conversational state over relatively large time horizon; a multi-turn
call in our setting often exceeds 20 minutes with several dozen turns from each speaker.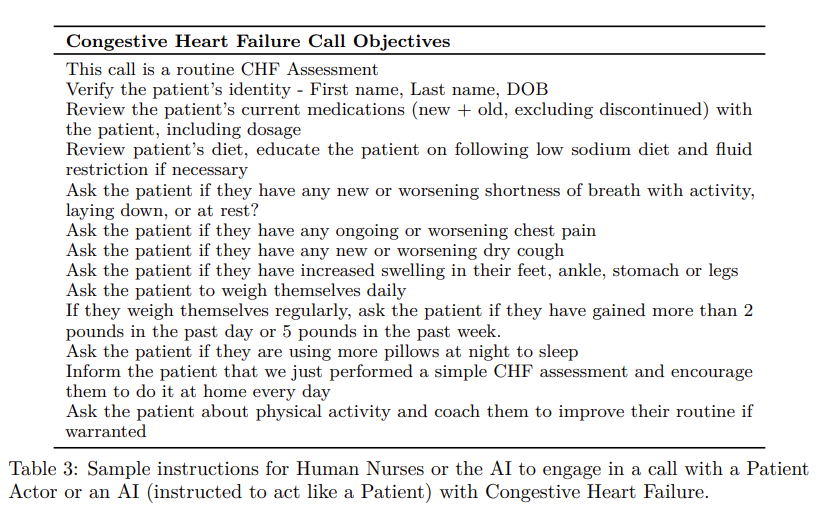
It is important to generate data which portrays tougher trajectories within the healthcare setting of our calls. Our system must be robust to handling patients with diverse profiles, for instance, high engagement with many questions or concerns; low regimen compliance; skepticism of AI health services, etc.
We thus rely on the domain expertise of medical professionals, US-licensed nurses in our setting, to generate accurate data which exhibits comprehensive coverage of our desired data distribution. We leverage a large number of registered nurses, patient actors and our AI-in-the-loop to generate simulated conversations. For targeted medical conditions (e.g., CHF, CKD) and procedures (e.g., post-discharge, pre-operative, chronic-care followups), clinicians create conversational scripts (refer to Table 3 for a simplified version of our CHF script). We also create a large number of fictional patient profiles with different medical histories, condition severity, medications, labs, lifestyle and personality traits (refer to Table4 for a sample patient profile).
We require clinical expertise to train all parts of Polaris. In order to do this, we employ a bootstrapping strategy for data generation. Initially, we generate conversations using registered nurses and patient actors. We design these conversations to cover a wide breadth of scenarios and behaviors on the part of the simulated patient. We give specific instructions to patient actors to converse such that many of the specialist agents are triggered, such as asking complex questions about medications, mispronouncing medicine names, providing deliberately confusing lab results (e.g., a blood glucose reading in response to a request for their blood pressure reading), asking about hospital specific information (e.g., where to park), etc. During these conversations the registered nurse annotates the transcripts for when these events occurred and what the specialist agents should do during corresponding turns.
We then proceed to train both the primary and support agents from this collection of datasets. This allows us to start using our trained agents in the conversation instead of nurses; their responses are reviewed by registered nurses with potential re-writes for the noisy turns. We also employ instruction tuned language models to perform data cleaning and augmentation. This is used to improve the style of responses and also create additional variety, preventing mode collapse in the primary agent distribution and ensuring robustness in the support agents. Like most bootstrapping situations, this process becomes more effective with more rounds of training, which allows generalization to new scripts, medications, and so on. Here we provide more details on the entities which participate in the data generation process.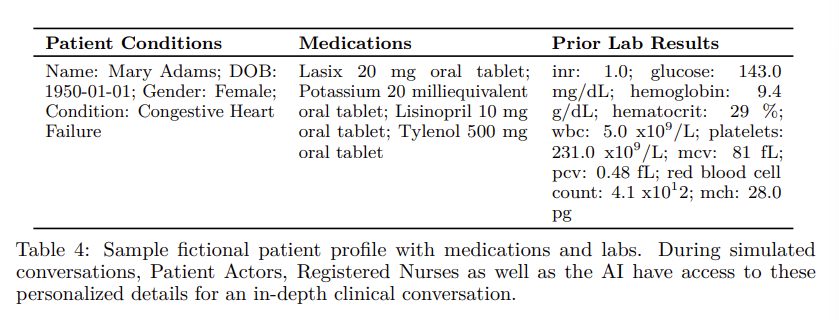
Patient Actors. Here the actors are asked to play the role of a fictional patient and portray a realistic patient experience. They are encouraged to use the fictional patient’s background as well as their personal experiences and feelings to guide them. We provide them with sample instructions, for instance: Ask about lab values - what they mean, whether they’re normal or not; state they’re taking the wrong medication dosages, or that they are taking medications not on their chart, and so on.
Registered Nurses. We ask the nurses to play the role of an ideal nurse at the bedside, on the phone, or in their community. While we provide them with the conversational script with defined call objectives, they are encouraged not to follow the order strictly, but instead follow the natural conversation trajectory for a realistic experience. This allows the patient at times to go on tangents, for instance, sharing their personal experiences that the nurse can engage with to develop rapport and trust; share their health concerns and symptoms that the nurse can both empathize with and educate on.
Our AI-in-the-Loop. Once our models are tuned with conversations generated from the earlier phases, we further use them to generate synthetic conversations. Here, the AI plays the role of a nurse with the conversational script and meta instructions used in the prompt as a preamble to converse with the patient actors. This stage is required primarily for tuning our support agents (discussed in Section 7) that generate tasks and provide relevant context to condition the primary agent to generate the response. After our support agent system is sufficiently tuned, we proceed to RLHF data generation. For this we sample multiple responses from the primary agent for the full prompt constructed from the meta-prompt, conversation history and support agent tasks. We leverage our registered nurses to give preference feedback to perform RLHF on the primary agent.