
1/22/24About 2 min
Approaches for prompt fine-tuning
| ID | Thought | Effect | Code |
|---|---|---|---|
| 1 | Using the definition to do directly | Result is not good | Code on Google Colab More details |
| 2 | Decompose the level definition, then to find the best match as the result based on the definition of levels and the question. Using lots of match methods to finetune. | Result is not good | Code on Google Colab More details |
| 3 | Finetune the model on OpenAI, and then to identify the level based on level definition and question Using three approaches to sample data for training, 1. Sample data from the shifting level dataset (Grouped sampling from each level randomly) 2. Sample data from overall dataset automatically (Grouped sampling from each level randomly) 3. Group sample data from all data randomly. | Result is still not good enough | Code on Google Colab |
| 4 | Using the GPT to summarize the definition for levels, then using the new definitions to create new prompt for getting result | Done | Code on Google Colab |
| 5 | Summarize the definition & finetuning groups data | Under the way | Code on Google Colab |
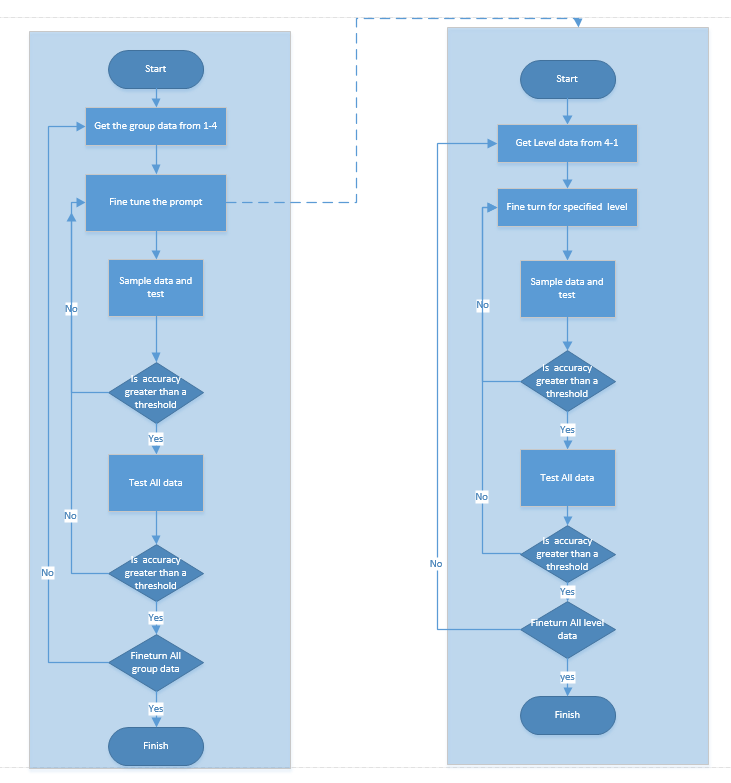
Prompt fine-tuning flowchart
Statistical consistency
This part will try to test the statistical consistency for different original levels.
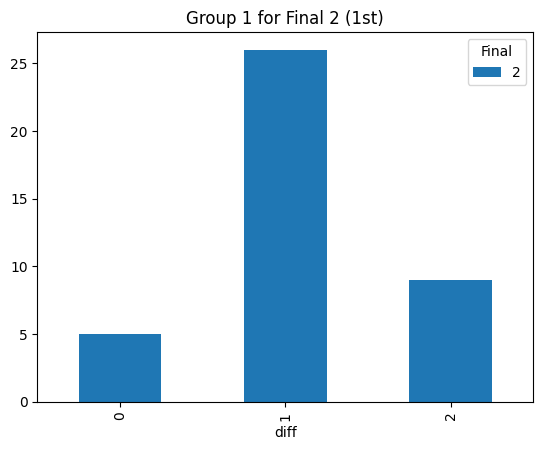
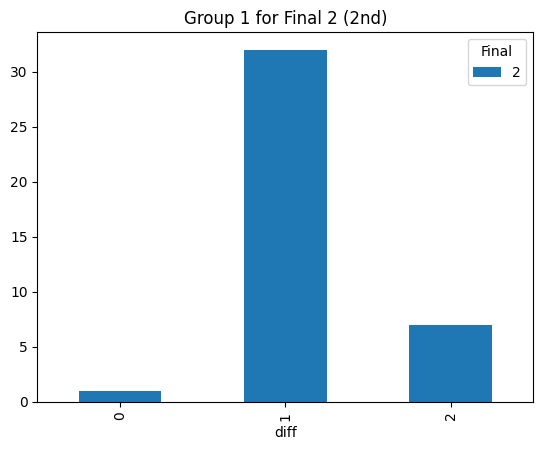
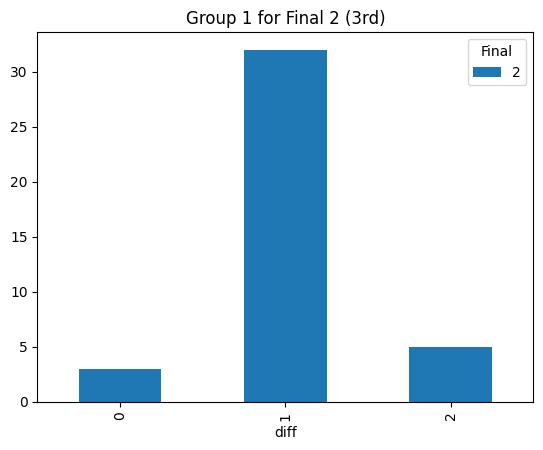
Statistical consistency (Final 2)
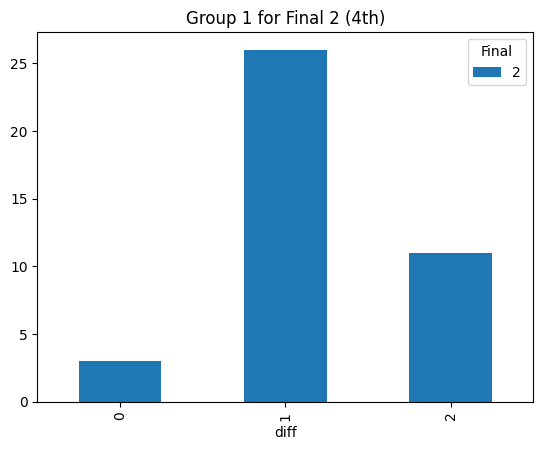
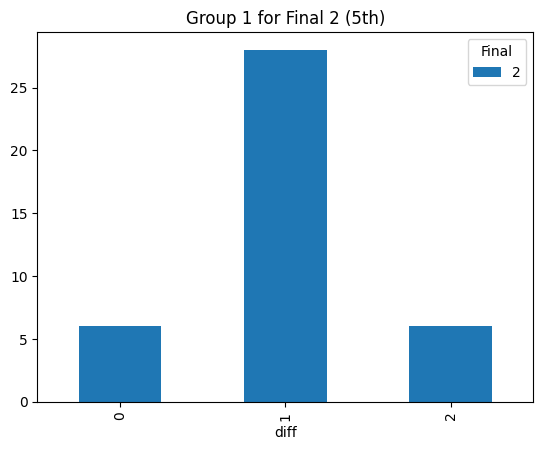
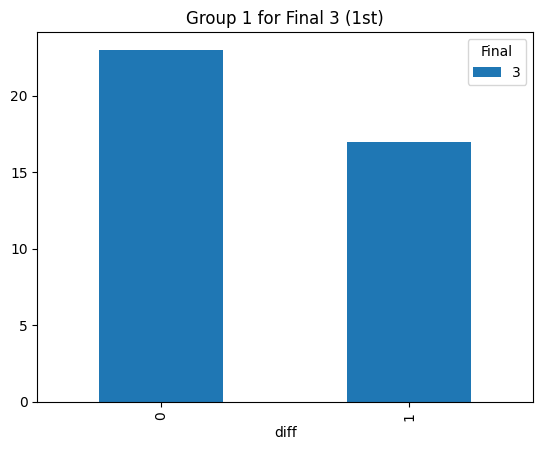
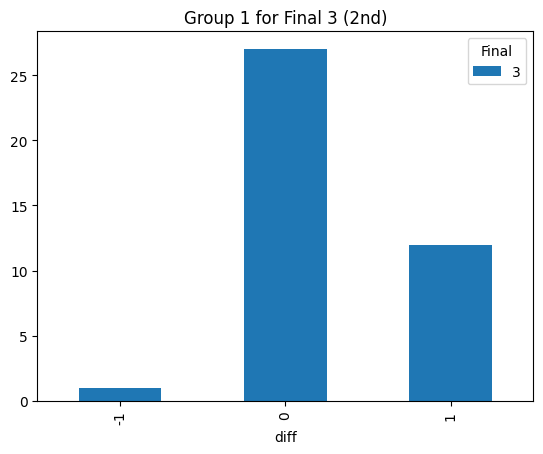
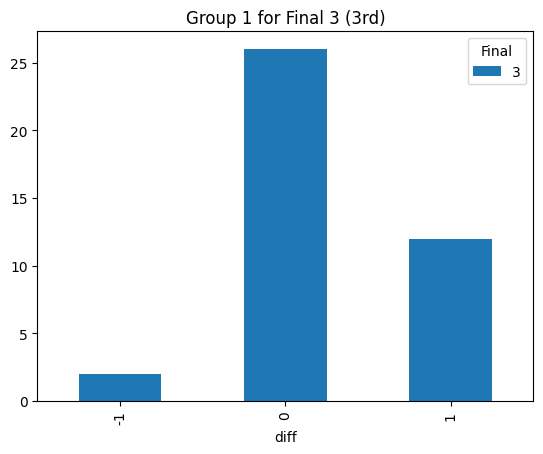
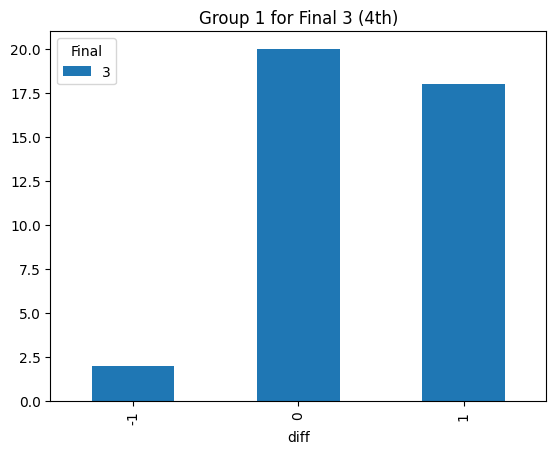
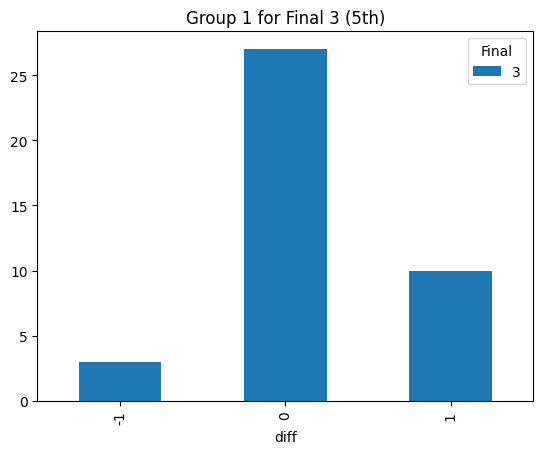
Statistical consistency (Final 3)
Statistical consistency (Final 4)
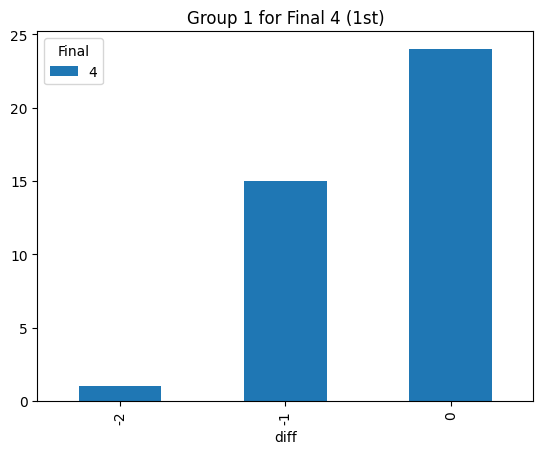
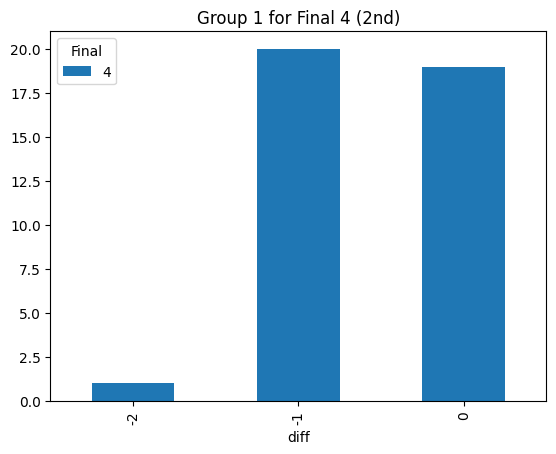
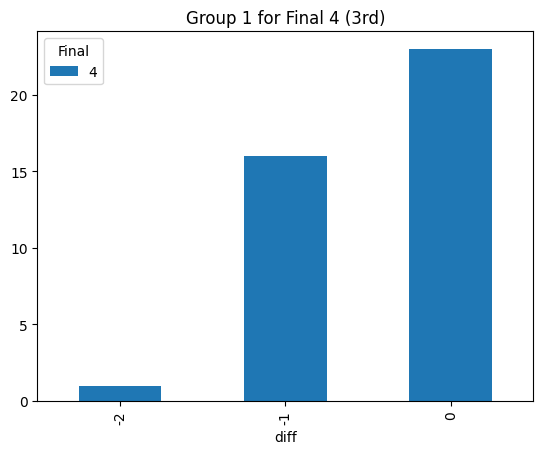
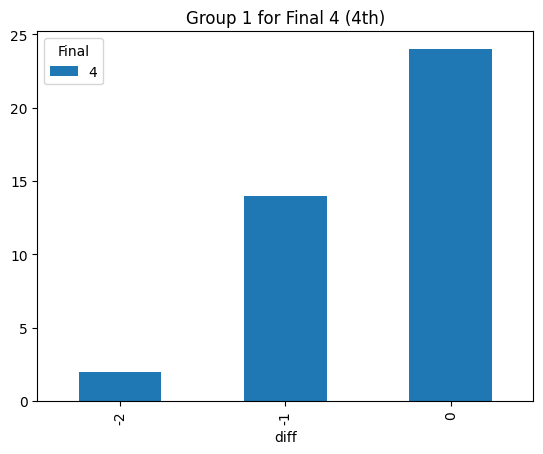
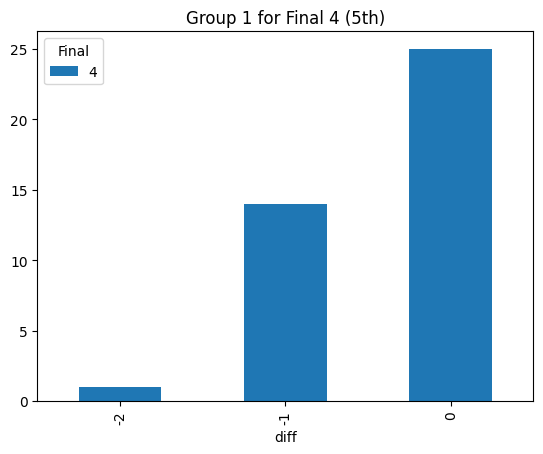
According to the graphs above, we can find the accuracy of classification for level 4 is low but it can be accepted for the initial step (Actually, the accuracy decreases rapidly after integrating the level 3. The accuracy could reach 90% before integrating the level 3 prompt). Most items keep the original level. According to the graphs above, most accuracy is around 60%, so the accuracy of the statistical result is consistent.